

Kubernetes coordinates a highly available cluster of computers that are connected to work as a single unit. Kubernetes automates the distribution and scheduling of application containers across a cluster in an efficient way.
- Service discovery and load balancing
- Storage orchestration
- Automated rollouts and rollbacks
- Self-healing
- Secret and configuration management
Problems with Containers without Orchestration
- Containers on different nodes cannot communicate with each other.
- When a container is replaced, a new IP address is assigned. Any hard-coded IP address will be broken.
- All containers on a single node share the host IP space and must coordinate the ports they use.
Kubernetes Objects
- Kubernetes is configured on one or more nodes.
- A node is a machine – physical or virtual – on which Kubernetes is installed.
- A node is a worker machine where containers are hosted.
- You need to have multiple nodes for high availability and scaling.
- A cluster is a set of nodes grouped together.
- The master (control plane) watches over the nodes in the cluster and is responsible for the actual orchestration of containers on the worker nodes.
- A node is a VM or a physical computer that serves as a worker machine in a Kubernetes cluster. Each node has a Kubelet, which is an agent for managing the node and communicating with the master.

- A pod is a Kubernetes abstraction that represents a group of one or more application containers (such as Docker), and some shared resources such as volumes (shared storage), networking (a cluster of IP addresses), and a spec (information about how to run a container)
- A pod hosts a single instance of an application.
- In general, a pod has a one-to-one relationship with a container, a single-container pod. But a single pod can have multiple containers of a different kind, a multi-container pod.
ReplicaSets

- A ReplicationController is an old feature.
- It ensures that a specified number of pod replicas are running at any one time.
- A ReplicaSet replaces a replication controller. It maintains a stable set of replica pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical pods.
- Load balancing and Scaling based on a pod template
- Providing fault-tolerance
- The main difference between a ReplicationController and a ReplicaSet is the “selector” element. Using the “selector” object, a ReplicaSet can manage pods that were created even before the Replicaset is created.
- [Note] A Deployment that configures a ReplicaSet is the recommended way to set up replication.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: myWeb
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: myweb
image: nginx
kubectl create –f rs.yaml --save-config
kubectl apply -f rs.yaml
kubectl get replicaset
kubectl get replicationcontrollers
kubectl delete replicaset <replicaset-name>
# update
kubectl replace –f rs.yaml
# scaling
kubectl scale –-replicas=6 –f rs.yaml
kubectl scale --replicas=6 replicaset <replicaset-name>
# editing
Kubectl edit replicaset <replicaset-name>
Deployments

- The deployment manages pods.
- Instructs Kubernetes on how to create and update instances of your application.
- Scaling ReplicaSets, which scale pods
- Supporting zero-downtime update and rollback by creating and destroying Replicasets
- Once you have created a deployment, the Kubernetes master schedules the application instances in that Deployment to run on individual nodes in the cluster.
- A Kubernetes Deployment Controller continuously monitors those instances and provides a self-healing mechanism to address machine failure or maintenance.
# creating a deployment
kubectl create deployment <deployment-name> --image=<image name>
# scaling
kubectl scale deployment –-replicas=3 <deployment-name>
# with labels
kubectl get deployment --show-labels
# filter with a specific label
kubectl get deployment –l app=nginx
Kubernetes Architecture/Components
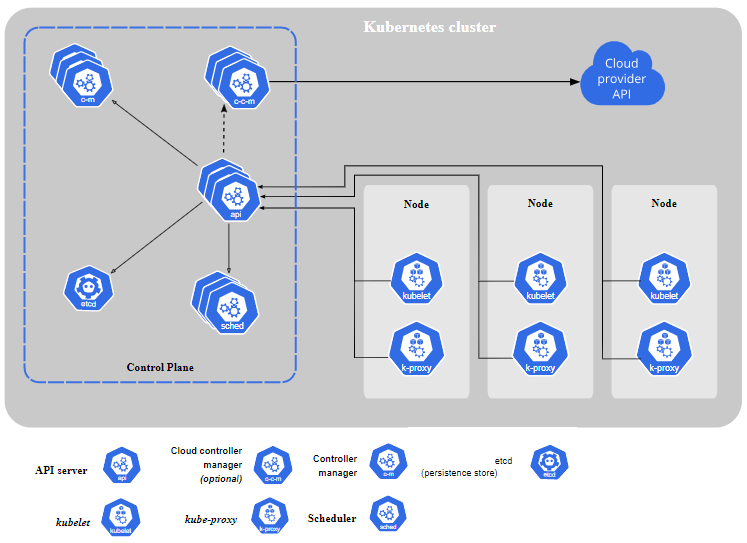
- Master
- kube-apiserver: The API server acts as the front-end gateway for Kubernetes. The users, management devices, command-line interfaces all talk to the API server to interact with the cluster.
- etcd key store: etcd is a distributed reliable key-value store used as Kubernetes’ backing store for all cluster data.
- etcd is responsible for implementing locks within the cluster to ensure there are no conflicts between the nodes.
- etcd stores the state of cluster objects and acts as the reference of the cluster. If the actual cluster is different from this, the cluster is changed to match.
- Scheduler: A scheduler is responsible for distributing work or containers across multiple worker nodes.
- When a new pod is created, the scheduler decides which node the pod will be run on.
- Controller: A controller makes decisions to orchestrate the working of the cluster and its nodes.
- kube-controller-manager
- Node controller
- Replication controller
- Endpoints controller
- Service Account & Token controllers
- cloud-controller-manager: runs controllers that are specific to your cloud provider.
- Node controller
- Route controller
- Service controller
- kube-controller-manager
- Worker node
- Kubelet: kubelet is the agent that runs on each worker node in the cluster. The agent is responsible for making sure that the containers are running on the nodes as expected.
- Kube-proxy: The proxy is responsible for networking within a cluster.
- kube-proxy uses the operating system packet filtering layer.
- A proxy provides network connectivity for services on the nodes. Services are defined via API.
- Container Runtime: The container runtime is the underlying software that is used to run containers. Docker is the most popular option.
Object Spec and Status
Almost every Kubernetes object includes two nested object fields:
- spec: the object’s desired state
- status: the object’s current state
The Kubernetes control plane continually and actively manages every object’s actual state to match the desired state you supplied.
Kubernetes Definition File – YAML
apiVersion:v1 # String
kind:Pod # String
metadata: # Dictionary
name: my-app
labels: # Dictionary
app: myapp
type: myapp-web
spec:
containers: # List
- name: nginx-container
image: nginx
ports:
- containerPort: 80
- A Kubernetes definition file always contains 4 top-level fields.
- apiVersion, kind, metadata, and spec
- They are all required fields.
- The “metadata” is a dictionary of key-value pairs, and so does the “labels.”
- Under metadata, you can only specify expected items such as “name ” or “labels.” You CANNOT add any other property under this.
- Under “labels“, you CAN have any kind of key or value pairs.
- The “spec” section is where you specify the desired state of a cluster.
- The “containers” section is a list or array of container settings.
Labels
- Labels are key/value pairs that are attached to objects.
- Labels specify identifying attributes of objects that are meaningful and relevant to users.
- Unlike names and UIDs, labels do not provide uniqueness.
- Labels are used to select and group the subsets of objects.
apiVersion: v1
kind: Pod
metadata:
name: my-app
labels:
app: web
type: frontend
env: dev
Label selectors
- Via a label selector, the client can identify a set of objects.
- Two types of selectors are supported
- equality-based (=, ==, !=)
- set-based (in, notin).
- Multiple conditions by comma (,) — act as a logical AND
kubectl get pods -l environment=production,tier=frontend
kubectl get pods -l 'environment in (production, qa)'
Annotations
- Annotations attach arbitrary non-identifying metadata to objects.
- Annotations are similar to labels to store custom metadata (as key-value pairs) for objects.
- Annotations cannot be used to select or group objects.
apiVersion: v1
kind: Pod
metadata:
name: my-app
annotations:
copyright: free
year: 2025
