

A Job creates one or more pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks the successful completions. When the specified number of successful completions is reached, the job is complete.
Jobs

A job runs container workloads until they complete, then shuts down the container(s).
Pod backoff failure policy
- Specify a non-zero positive number to “spec.completions”
- The job is regarded as completed when there are the specified number of successful pods.
- The default is 1.
- By default, a new pod will created once the pod succeeds or fails. If you want to run multiple pods at once, you can specify “spec.parallelism”
- The default is 1.
- Set “spec.backoffLimit” to specify the number of retries before considering a Job as failed.
- The back-off limit is set by default to 6.
- Set “spec.activeDeadlineSeconds” to automatically terminate the job.
- Once a Job reaches activeDeadlineSeconds, all of its running Pods are terminated and the Job status will become type: Failed
- .spec.activeDeadlineSeconds takes precedence over its .spec.backoffLimit.
- The restartPolicy for a job must be “OnFailure” or “Never“.
apiVersion: batch/v1
kind: Job
metadata:
name: my-job
spec:
completions: 4
parallelism: 2
activeDeadlineSeconds: 30
backoffLimit: 4
template:
spec:
containers:
- name: job-container
image: busybox
command: ['echo', 'Hello World']
restartPolicy: Never
kubectl create job my-job --image=busybox --dry-run=client -o=yaml > job.yaml
# modify job.yaml
kubectl apply –f my-job.yaml
kubectl get jobs
kubectl describe job <job-name>
kubectl get pods –-selector=job-name=<job-name>
kubectl get pods –l=job-name=<job-name>
kubectl logs <pod-name>
kubectl delete job <job-name>
CronJobs

A CronJob re-runs a job periodically according to a schedule.
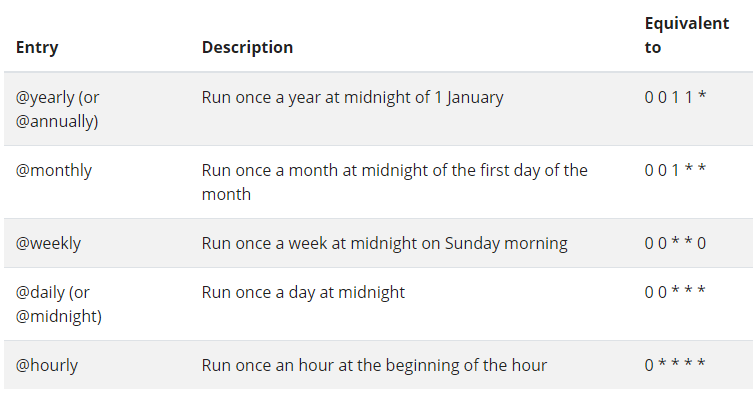
spec.schedule
The schedule consists of 5 components
- minute (0 – 59)
- hour (0 – 23)
- day of the month (1 – 31)
- month (1 – 12)
- day of the week (0, Sunday – 6, Saturday)
- The restartPolicy for a cron job must be “OnFailure” or “Never“.
apiVersion: batch/v1
kind: CronJob
metadata:
name: my-cronjob
spec:
schedule: "*/1 * * * *" # every minute
jobTemplate:
spec:
template:
spec:
containers:
- name: job-container
image: busybox
command: ['/bin/sh', '-c', 'date']
restartPolicy: OnFailure
kubectl create cj my-cronjob --image=busybox --schedule="*/1 * * * *" --dry-run=client -o=yaml > my-cronjob.yaml
# modify my-cronjob.yaml
kubectl apply –f my-cronjob.yaml
kubectl get cronjobs
# check the event and find the job name
kubectl describe cronjob <cronjob-name>
kubectl get pods
kubectl logs <pod-name>
kubectl delete cronjob <cronjob-name>
